
This article is about “What is noise in data mining MCQ”, hope you will like the information. If yes please do share it with others. What is noise or error in data in data mining?, Impact of having noise in data / noisy data?, Which learning method, algorithm or popular technique commonly used for handling the noise in data mining?, What happens in clustering method like k-means that is used to handle noise or noisy data in data mining?, What happens in regression method used to handle noise or noisy data in data mining?, What is the other name one can give to noise in data or noisy data in data mining or machine learning tasks? etc.
Table of Contents
Introduction:
Noise = Junk information occupying database space handled using clustering, regression etc.
How can datasets acquire noisy data?
Noisy data or junk or irrelevant data can enter in the dataset because of several reasons like:
- Data entry errors i.e. while entering the data typos or incorrect data entry has happened,
- Measurement errors: The instruments that is used to record the data has certain issues like it started malfunctioning,
- Outliers: Some values are genuine but are outliers i.e. exception which can hamper the final results interpretation,
- Duplicate entries: Some values are entered multiple times because of some issue,
- Missing values: Certain values are missing or because of some issue were not recorded in the database,
- Special characters are embedded in the system that system is in itself not able to read etc.
So, above mentioned reasons are not comprehensive every now and then some other possible reason can cause noise in the system.
Q1. What is noise or error in data in data mining?
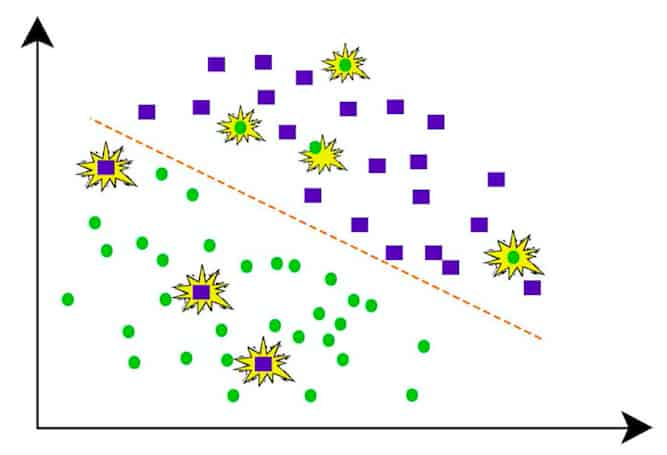
A. Large amount of very useful information
B. Large amount of meaningless information
C. Low amount of very useful information
D. Low amount of meaningless information
Ans. B. Large amount of meaningless information
Example of noisy data in data mining:
If database has huge amount of data out of which only 10% is of use and remaining 90% is junk, then 90% data is nothing but noise.
Businesses now-a-days spends money and human efforts to clean data and make it usable.
Also read about: The basic difference between noise and outliers in Data
So, do not confuse noise with outliers.
Q2. Impact of having noise in data / noisy data?

A. Increases amount of storage space required
B. Decreases amount of storage space required
C. No impact on amount of storage space required
D. None of the above
Ans. A. Increases amount of storage space required
Now, as discussed in Que.1 that a big chunk of your data is junk, but that gets stored in your database somehow creating the requirement of big database and cost associated with it.
Now, some databases charge for every byte of data processed or queried. So, if your data is increasing because of noise so do the cost of querying it, processing it and cleaning it to get the accurate and clean data.
Q3. Which learning method, algorithm or popular technique commonly used for handling the noise in data mining?
A. Clustering
B. Binning
C. Regression
D. All of the above
Ans. D. All of the above
Binning smooths the corrupted data and hence is used to handle noise in data.
Other useful techniques to find out noise in data are: clustering method, support vector machine (SVM) algorithm etc.
Source: ques10
Q4. What happens in clustering method like k-means that is used to handle noise or noisy data in data mining?
A. Data is organised into clusters
B. Data is arranged in a line
C. Any of the above
D. None of the above
Ans. A. Data is organised into clusters and the values lying outside of it are considered as outliers
Same kind of points or points of similar quality lies together and the ones that are different remains far outside of the common area, hence the ones that are quite similar and lying together are said to lie in cluster and the ones lying outside of it are outliers.
Q5. What happens in regression method used to handle noise or noisy data in data mining?
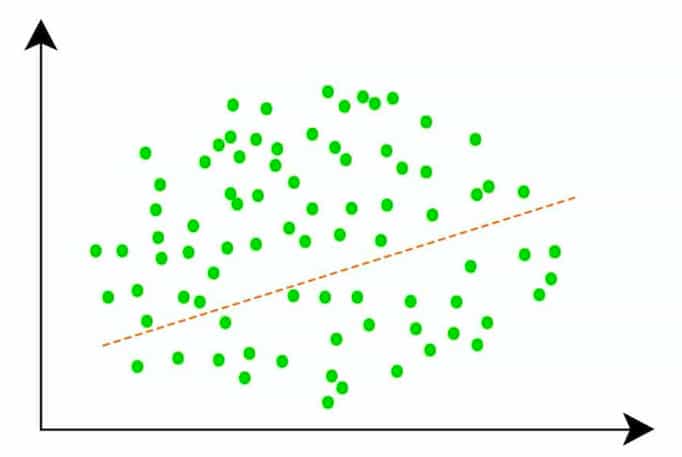
A. One finds the best fit line
B. Data is grouped into clusters
C. Data is grouped into bins
D. All of the above
Ans. A. One finds the best fit line and using it’s equation one can find the value of dependant variable using another variable.
If one wants to find an easy solution to locate and remove outliers then drawing a best fit straight line is the easiest and quick solution, then depending on need the points lying in it’s 20% or 30% or 40% range can be called as useful data and the ones lying outside of it as outliers.
Q6. What is the other name one can give to noise in data or noisy data in data mining or machine learning tasks?
A. Corrupt data
B. Outliers
C. Both a and b
D. None
Ans. A. Corrupt data
We can call it corrupt data but not outlier as it includes errors or actual data whose value is too large or too low w.r.t other majority of values.
Q7. What is the opposite of noisy data and why it is meaningless? Explain with example. And what are the benefits of accurate data mining or machine learning tasks.
Anything that is not noise is good data, but will it be helpful for your analysis or not depends on the problem you are trying to solve using the data.
For e.g. suppose your dataset is about different sports and players in it, now if you want data of baseball related players and if you are getting data of basketball players then that is of no use to you.
In context of data mining noise or noisy data is meaningless data i.e.
– The data which is not right, -or-
– Data that is too high or too low in value with respect to original dataset, hence not suitable to generate insights;
– Dataset which has errors like corrupt data etc.
So, opposite of noisy data will be data, which is quite accurate and can be used to generate correct and valuable information or insights.
Here, by insight I mean to say such information which is not readily visible by eyes and that can impact final decision positively.
Hence, the main difference between noisy data and correct data is that the correct data is much valuable as the information it gives is very accurate, can be used to predict outcomes correctly and hence impacts final decision positively.
On the other hand noisy data is full of errors and outliers, which always gives incorrect picture of what will happen.
Example of noisy data in data mining:
- Value too high or too low w.r.t best fit line or group of points or cluster,
- Having text data in numerical column or vice-versa,
- Corrupted or inappropriate unreadable data gets stored in database,
- Test data created while testing etc.
What is called as noise in data / reason for noise generation:

- Corrupt data because of error in codes, hence while trying to use the data it will start throwing error;
- Errors because of malfunctioning part leading to generation of too much data,
- Hardware failures, hence leading to generation and logging of wrong data in database,
- Programming error etc.
Benefits of handling/removing noise in data mining:
- Decreases time to train the model because no extra data needs to be processed;
- Accuracy of final output increases as only the accurate data is input, hence chances of garbage in garbage out nullifies;
- Decreases storage space required to store data, as we are not dealing with unwanted data;
- Better decision making due to higher accuracy of final output etc.
Other useful articles:
Similar Articles:
Final words:

So, this is all about “What is noise in data mining MCQ”, do let us know in comment section what else you want to read about or some other information you require in the current topic i.e. “What is noise in data mining MCQ”, we are more than happy to help you.
FAQs:
Q1. What is the difference between outlier and noise?
Ans. Noise is error or unwanted data that can be generated because of n number of reasons, but these are errors that should be removed from the system.
Outliers are values that are too high or too low w.r.t majority of the values, it can be correct as well as incorrect values.
If outlier is representing correct values then it tells something interesting about the system or dataset.
If noise is not removed then it will give false information during analysis about the system. On the other hand if outliers are not error and present in the system then on finding the average it messes up the final average value i.e. why it is important to remove outliers from the system.
Noise should be removed because if we start training some algorithm on it, then that will consider noise as pattern and will produce results accordingly, which is not right.
Q2. What causes noisy data?
Ans. Human mistakes and/or inaccurate instruments are two primary reason for noise in data.
Q3. How to manage noisy data?
Ans. There can be several ways to manage noisy data:
a. Doing RCA and rectifying issue: If data collection happening in an automated manner for e.g. in digital products then doing the root cause analysis and rectifying the issue that is leading to generation of this noisy data, otherwise over a period of time this will increase to an insane amount.
b. Increasing the data size: If data collection happening manually for e.g. say some company is doing door to door survey for launch of their new product, then in that case some users might have filled the form in bad mood and so their review can’t be considered genuine. In such cases it’s good to increase the size of dataset to huge extent, so that such small errors don’t give false results.
1 thought on “What is noise in data mining MCQ?”